Hi! Ayaroo here again, im having some problems trying to reply to the latest post (some trouble with the verification with cloudflare...). Already opened a ticket to itch.io...
Im sorry to open a new coment, but thanks for the quick reply.
I errased all old files and then reinstalled the new update but still gives me the same result...
I haven't touched any default settings and tried to do the things that you told me (changing the OCR language and then back again to japanese) and also tried on some easier text ingame (the settings, the imaged attached should say "screen size" or something like that) but still somehow messes up...
I know it must be a problem on my side, because on your end it works as expected.
Thanks in advance for your hard work and hope we can find a solution to my problems... :)
Hello! I've yet to test the program because it wont translate correctly. Im playing a game where the text is a bit artistic and i think the model doesnt translate correctly. and the text changes without moving the source. it just start saying "im sorry im sorry im sorry" and then keep on saying uncontroled things
If you need more information, just ask me because i want the translator to work because i have a few more games to try. I'm using the Pixel text OCR mode and everything on auto
I’ve just released a hotfix update that improves OCR/translation synchronization and fixes several UI issues.
Please download the latest version to make sure everything works correctly on your side.
A small clarification regarding the Pixel / Artistic Text OCR mode:
Even though Thaluna supports this mode, please be aware that artistic or hand-drawn fonts used in some games can produce inconsistent results.
This is normal behavior for ALL OCR engines — when fonts are stylized, the model can interpret shapes differently on each pass.
So even if the line is read correctly once,
the same screenshot may produce a slightly different result next time.
It depends on how the artistic shapes are interpreted.
I tested your screenshot here and it works correctly, but different games and unique font styles can still cause unpredictable OCR outputs in Pixel mode.
If you ever get weird results, switching briefly to:
Standard OCR,
then back to Pixel,
or changing OCR language temporarily
usually forces a clean reset and fixes the issue.
Let me know if the new hotfix solves your problem!
Oi! Obrigado por entrar em contato e avisar sobre o problema. 💜 Analisei o erro e ele não é causado pelo Thaluna, mas sim por uma biblioteca ausente no seu Windows.
Para corrigir, basta instalar um pacote oficial da Microsoft chamado Visual C++ Redistributable — é o mesmo usado por muitos jogos e programas.
2️⃣ Na página, procure a seção chamada “Visual Studio 2015, 2017, 2019 e 2022” e clique no link X64 (para Windows 64-bit) para baixar o instalador. 3️⃣ Execute o instalador e, quando terminar, reinicie o computador.
Depois disso, o Thaluna deve abrir normalmente. Se ainda tiver problemas, me avise aqui — terei prazer em te ajudar!
El traductor debería funcionar sin configuración inicial, pero hay algunos pasos importantes:
1️⃣ Selecciona el modelo de traducción correcto (por ejemplo “Japanese → English”). 2️⃣ Elige el idioma OCR del texto en pantalla (por ejemplo “Japanese”). 3️⃣ Asegúrate de que la traducción no esté en pausa (si ves ▶️, haz clic para iniciar).
Ten en cuenta que el primer inicio puede tardar un poco más de lo normal, ya que Thaluna necesita inicializar algunos procesos en segundo plano antes de empezar a traducir.
Si después de un rato aún no traduce, intenta reiniciar la aplicación o mover ligeramente el marco de captura. También puede que el equipo sea demasiado lento para el modelo seleccionado, aunque esto es poco común.
Si el problema continúa, por favor envíame una captura de pantalla y te ayudaré a resolverlo.
Heeeelp, I am new to using this program. I just recently downloaded the full version, and this error keeps appearing, and I don't know what else to do :c
That error happens when Thaluna tries to use GPU acceleration (PaddleOCR-GPU) but CUDA/cuDNN isn’t available on your system.
This is already fixed — the next patch will automatically switch to CPU mode instead of closing the app.
For now, you can fix it manually: 1️⃣ Go to the folder where Thaluna is installed. 2️⃣ Open the subfolder _internal. 3️⃣ Find the file config.json. 4️⃣ Open it with Notepad. 5️⃣ Find the line "ocr_device": "cuda" and change it to "cpu". 6️⃣ Save and restart Thaluna.
The issue you reported has been fixed in version 2.2 — Thaluna now automatically switches to CPU if GPU initialization fails. You can simply re-download the latest version and it should run fine👍
Manga mode needs some work. Mainly using it for JP->Eng manga translation and it can't seem to play nice with any Ollama models I give it. Still don't regret the purchase and am eagerly awaiting the next update!
I think I see what happened. In Lens Mode the OCR engine is designed for horizontal text, so if you’re working with vertical Japanese it can give messy input to Ollama models. That’s why things didn’t line up.
For vertical manga, the real-time mode with Settings → OCR Mode → Manga (Vertical Text) works much better. It won’t auto-box everything perfectly, but you can move the capture box between bubbles and it should give cleaner results. If it’s horizontal text, Lens Mode should already be fine.
I also plan to improve Lens Mode so it handles vertical Japanese properly in a future update — it’s definitely on my list.
By the way, when you said it “can’t seem to play nice with any Ollama models,” did you mean the translations came out as nonsense, or just random characters? That info would help me a lot to confirm if OCR was the real issue.
Thanks again for using Thaluna, and for taking the time to share your experience. Feedback like this really helps me improve the app, and I’m happy to hear you’re using it for manga.
I was mainly using the cropper next to the snapshot button. With the base model, it would kinda work, but I've got a decent pc so I tried hooking it up to some larger models. Gemma was hopeless and would just try to talk to me instead of properly translating, and more notably mistral kept either spewing out symbols (+kr, ++__++ and such) or saying that there's nothing to translate.
I did have it set to vertical, though I didn't use the drag box much as it kept getting distracted.
Gonna try hooking it up to my best boy DeepSeek to check if it's just the models being weird.
Hoping for your success, this shit is groundbreaking.
Thanks a ton for testing all that, really appreciate it In my case Gemma 3:4B actually worked fine for translations, but yeah, it can vary a lot depending on the text/setup. Super curious how DeepSeek will work for you!

← Return to tool
Comments
Log in with itch.io to leave a comment.
Hi! Ayaroo here again, im having some problems trying to reply to the latest post (some trouble with the verification with cloudflare...). Already opened a ticket to itch.io...
Im sorry to open a new coment, but thanks for the quick reply.
I errased all old files and then reinstalled the new update but still gives me the same result...
I haven't touched any default settings and tried to do the things that you told me (changing the OCR language and then back again to japanese) and also tried on some easier text ingame (the settings, the imaged attached should say "screen size" or something like that) but still somehow messes up...
I know it must be a problem on my side, because on your end it works as expected.
Thanks in advance for your hard work and hope we can find a solution to my problems... :)
Hi! Thanks again
I want to help you solve this as quickly as possible, so I just need a few small details:
1️⃣ Windows Display Scaling
What scaling are you using in Windows?
100%
125%
something else?
(High scaling can sometimes affect OCR.)
2️⃣ Does Snapshot Mode work normally?
When you select text manually with Snapshot Mode,
is the translation correct?
This helps me see whether the problem is Real-Time OCR or the game itself.
3️⃣ Small test
Could you try putting the Real-Time window over a simple Japanese webpage (like Wikipedia JP)?
👉 Does it translate correctly there?
If yes, then the issue is specific to the way the game renders text.
That’s all I need for now — thank you again for your patience! 😊
Hello! I've yet to test the program because it wont translate correctly. Im playing a game where the text is a bit artistic and i think the model doesnt translate correctly.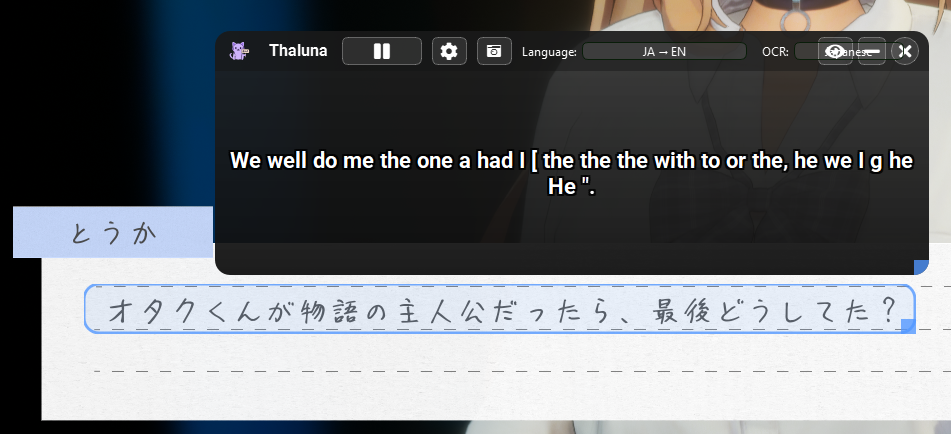
and the text changes without moving the source. it just start saying "im sorry im sorry im sorry" and then keep on saying uncontroled things
If you need more information, just ask me because i want the translator to work because i have a few more games to try.
I'm using the Pixel text OCR mode and everything on auto
Thanks in advance
Thanks again for the report — I tested the same Japanese sentence on my side and I was able to reproduce the issue.
It looks like the OCR + translation pipeline didn’t fully refresh after switching languages, which can cause unstable output or repeated text.
Here’s an easy temporary fix:
Switch the translation model to any other one (for example EN→PL or EN→EN).
Switch the OCR mode to a different one just for a moment.
Then switch everything back to your preferred setup:
Translation: Japanese → English
OCR: Japanese
This forces a full internal reset, and after doing this the translation should work correctly again.
I tested the same line using the standard Japanese OCR mode and it worked fine after resetting it this way.
If you want higher-accuracy translations, models from Ollama (like gemma3:4b) generally give better JA→EN results than the default built-in model.
For this game, please switch from Pixel Text OCR to the Standard Japanese OCR mode — that’s the one I tested and confirmed working correctly.
I’ll patch this behavior in the next update so the workaround won’t be necessary anymore.
Thanks again for helping improve the app!
Here’s the result I got on my side after the reset on ollama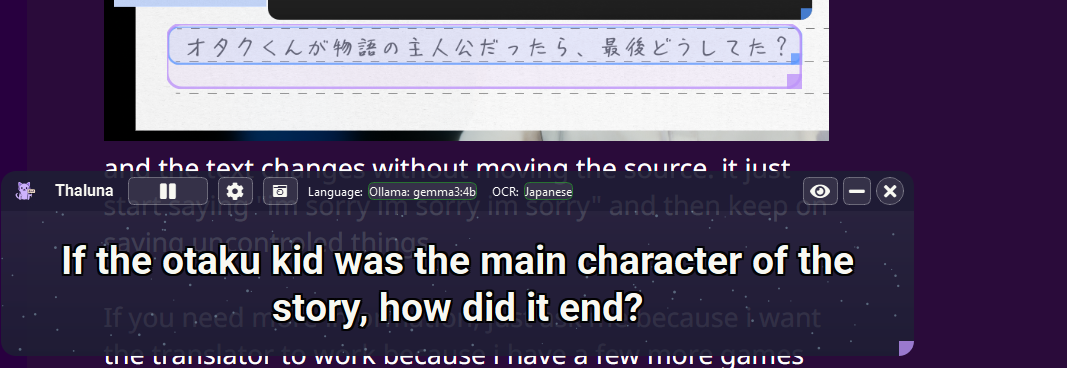
Hi again!
I’ve just released a hotfix update that improves OCR/translation synchronization and fixes several UI issues.
Please download the latest version to make sure everything works correctly on your side.
A small clarification regarding the Pixel / Artistic Text OCR mode:
Even though Thaluna supports this mode, please be aware that artistic or hand-drawn fonts used in some games can produce inconsistent results.
This is normal behavior for ALL OCR engines — when fonts are stylized, the model can interpret shapes differently on each pass.
So even if the line is read correctly once,
the same screenshot may produce a slightly different result next time.
It depends on how the artistic shapes are interpreted.
I tested your screenshot here and it works correctly, but different games and unique font styles can still cause unpredictable OCR outputs in Pixel mode.
If you ever get weird results, switching briefly to:
Standard OCR,
then back to Pixel,
or changing OCR language temporarily
usually forces a clean reset and fixes the issue.
Let me know if the new hotfix solves your problem!
Não consigo abrir, da este erro.
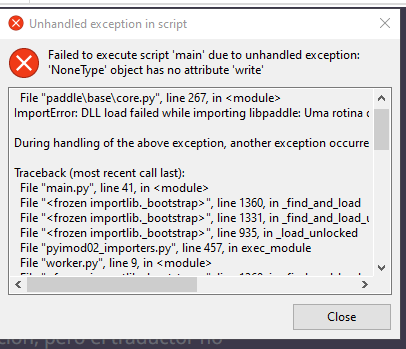
Oi!
Obrigado por entrar em contato e avisar sobre o problema. 💜
Analisei o erro e ele não é causado pelo Thaluna, mas sim por uma biblioteca ausente no seu Windows.
Para corrigir, basta instalar um pacote oficial da Microsoft chamado Visual C++ Redistributable — é o mesmo usado por muitos jogos e programas.
Siga estes passos:
1️⃣ Acesse a página oficial da Microsoft:
👉 https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist
2️⃣ Na página, procure a seção chamada “Visual Studio 2015, 2017, 2019 e 2022” e clique no link X64 (para Windows 64-bit) para baixar o instalador.
3️⃣ Execute o instalador e, quando terminar, reinicie o computador.
Depois disso, o Thaluna deve abrir normalmente.
Se ainda tiver problemas, me avise aqui — terei prazer em te ajudar!
Hola, descargué la aplicación, pero el traductor no funciona. ¿Necesito alguna configuración para que comience a traducir?
¡Hola! 😊 Gracias por probar Thaluna.
El traductor debería funcionar sin configuración inicial, pero hay algunos pasos importantes:
1️⃣ Selecciona el modelo de traducción correcto (por ejemplo “Japanese → English”).
2️⃣ Elige el idioma OCR del texto en pantalla (por ejemplo “Japanese”).
3️⃣ Asegúrate de que la traducción no esté en pausa (si ves ▶️, haz clic para iniciar).
Ten en cuenta que el primer inicio puede tardar un poco más de lo normal, ya que Thaluna necesita inicializar algunos procesos en segundo plano antes de empezar a traducir.
Si después de un rato aún no traduce, intenta reiniciar la aplicación o mover ligeramente el marco de captura.
También puede que el equipo sea demasiado lento para el modelo seleccionado, aunque esto es poco común.
Si el problema continúa, por favor envíame una captura de pantalla y te ayudaré a resolverlo.
Heeeelp, I am new to using this program. I just recently downloaded the full version, and this error keeps appearing, and I don't know what else to do :c
Hey! 😊 Thanks for reporting this.
That error happens when Thaluna tries to use GPU acceleration (PaddleOCR-GPU) but CUDA/cuDNN isn’t available on your system.
This is already fixed — the next patch will automatically switch to CPU mode instead of closing the app.
For now, you can fix it manually:
1️⃣ Go to the folder where Thaluna is installed.
2️⃣ Open the subfolder
_internal.3️⃣ Find the file
config.json.4️⃣ Open it with Notepad.
5️⃣ Find the line
"ocr_device": "cuda"and change it to"cpu".6️⃣ Save and restart Thaluna.
After that, it’ll work normally
The issue you reported has been fixed in version 2.2 — Thaluna now automatically switches to CPU if GPU initialization fails.
You can simply re-download the latest version and it should run fine👍
Manga mode needs some work. Mainly using it for JP->Eng manga translation and it can't seem to play nice with any Ollama models I give it.
Still don't regret the purchase and am eagerly awaiting the next update!
Hi,
Thanks a lot for your feedback 💜
I think I see what happened. In Lens Mode the OCR engine is designed for horizontal text, so if you’re working with vertical Japanese it can give messy input to Ollama models. That’s why things didn’t line up.
For vertical manga, the real-time mode with Settings → OCR Mode → Manga (Vertical Text) works much better. It won’t auto-box everything perfectly, but you can move the capture box between bubbles and it should give cleaner results. If it’s horizontal text, Lens Mode should already be fine.
I also plan to improve Lens Mode so it handles vertical Japanese properly in a future update — it’s definitely on my list.
By the way, when you said it “can’t seem to play nice with any Ollama models,” did you mean the translations came out as nonsense, or just random characters? That info would help me a lot to confirm if OCR was the real issue.
Thanks again for using Thaluna, and for taking the time to share your experience. Feedback like this really helps me improve the app, and I’m happy to hear you’re using it for manga.
I was mainly using the cropper next to the snapshot button. With the base model, it would kinda work, but I've got a decent pc so I tried hooking it up to some larger models. Gemma was hopeless and would just try to talk to me instead of properly translating, and more notably mistral kept either spewing out symbols (+kr, ++__++ and such) or saying that there's nothing to translate.
I did have it set to vertical, though I didn't use the drag box much as it kept getting distracted.
Gonna try hooking it up to my best boy DeepSeek to check if it's just the models being weird.
Hoping for your success, this shit is groundbreaking.
Thanks a ton for testing all that, really appreciate it
In my case Gemma 3:4B actually worked fine for translations, but yeah, it can vary a lot depending on the text/setup. Super curious how DeepSeek will work for you!
Great tool, you've done a great job, keep it up!
Are there any plans to implement this on Linux? Since I definitely won't be using Windows,
it would be a shame if there were no Linux version.
Thank you so much for the kind words! Thaluna currently works on Windows, but I’ll see what I can do about a Linux version down the line.